Dalam laporan karya ilmiah, peneliti tidak hanya
melaporkan hasil dari uji hipotesisinya dengan statistik inferensial saja,
tetapi juga memberikan deskripsi dari data yang diperoleh. Hal ini dilakukan
untuk memberikan informasi bagi pembaca awam serta kedalaman dalam pembahasan.
Pada umumnya bagian deskriptif subjek memuat
gambaran mengenai jumlah subjek yang dianalisis berdasarkan
karakteristik mereka yang relevan (seperti jenis kelamin, usia, pendidikan,
dll). Deskripsi subjek kemudian diikuti oleh deskripsi data penelitian yang
memuat statistik deskriptif pada masing-masing variabel yang dianalisis, seperti
banyaknya subjek (n), mean (M), deviasi standar (s), varians (s2),
skor minimum (Xmin), dan skor maksimum (Xmaks). Dari
informasi deskriptif yang diperoleh tadi, kita dapat mengetahui keadaan subjek
pada aspek alau variabel yang diteliti.
Salah satu manfaat kita mengetahui itu adalah untuk
mengkategorikan subjek kita memiliki skor skala yang tinggi, sedang, atau
rendah. Oleh karena itu, tulisan kali ini akan memaparkan bagaimana cara
membuat kategorisasi skor subjek dari hasil pengukuran skala dengan SPSS.
Membuat kriteria
kategorisasi
Langkah pertama untuk kita membuat kategorisasi adalah
dengan menetapkan kriterianya terlebih dahulu. Ini juga tidak terlepas dari
berapa jumlah kategori yang akan kita buat, misalkan 3 kategori (rendah,
sedang, tinggi), atau 5 kategori (sangat rendah, rendah, sedang, tinggi, sangat
tinggi). Penentuan kategori ini dadasari atas asumsi bahwa skor populasi subjek
terdistribusi secara normal. Distribusi normal terbagi atas enam bagian atau
enam satuan deviasi standar, seperti pada gambar di bawah.
Untuk mengkategorikan hasil pengukuran menjadi tiga
kategori, pedoman yang bisa digunakan adalah:
Rendah
|
X < M – 1SD
|
Sedang
|
M – 1SD < X < M + 1SD
|
Tinggi
|
M + 1SD < X
|
Sedangkan jika ingin membuat lima kategori, pedoman yang
bisa digunakan adalah:
Sangat Rendah
|
X < M – 1,5SD
|
Rendah
|
M – 1,5SD < X < M – 0,5SD
|
Sedang
|
M – 0,5SD < X < M + 0,5SD
|
Tinggi
|
M + 0,5SD < X < M + 1,5SD
|
Sangat tinggi
|
M + 1,5SD < X
|
Keterangan:
M = Mean
SD = standar deviasi
*Panduan kategorisasi ini dapat dilihat di buku Azwar
(2012).
Sebenarnya tidak ada pedoman khusus tentang berapa jumlah
kategori yang ingin kita buat dan berapa batasan skor pada masing-masing
kategori. Pedoman di atas hanyalah pedoman yang dibuat oleh salah satu ahli
dalam bidang pengukuran. Meskipun demikian, peneliti bisa memodifikasi kreteria
yang dibuat sesuai dengan kebutuhannya, asalkan tetap logis dan proporsional.
Misalkan, saya punya contoh skala asertivitas model skala
likert dengan skala 1-5. Jumlah item dalam skala tersebut adalah 12. Saya ingin
menkategorikan subjek ke dalam 3 kelompok, yakni rendah, sedang, dan tinggi.
Dengan demikian, jika subjek menjawab nilai paling rendah semua, yakni 1, maka
skor yang mungkin didapatkan adalah 1x12 = 12 (Xmin). Sedangkan jika
subjek menjawab nilai paling tinggi semua, yakni 5, maka skor yang mungkin
didapatkan adalah 5x12 = 60 (Xmaks). Dengan demikian Range dari data
tersebut adalah 60-12 = 48. Karena kita tahu bahwa kurve normal terdiri atas 6
standar deviasi, maka tiap standar deviasi nilainya adalah 48/6=8. Kita juga
tahu bahwa dalam kurve normal, nilai mean selalu berada di tengah, dengan
demikian mean = (12+60) / 2 = 36.
Xmin = 12
Xmaks = 60
Range = Xmaks – Xmin
= 60-12 = 48
Mean = (Xmaks + Xmin)
/ 2
= (12+60) / 2 = 36
SD = Range / 6
= 48/6 = 8
Karena kita sudah mendapatkan nilai mean dan SD, maka
kita bisa membuat kriteria kategorisasi berdasarkan pedoman yang sudah ada.
Rendah
|
X < M – 1SD
X < 36 – 8
X < 28
|
Sedang
|
M – 1SD < X < M + 1SD
36 – 8 < X < 36 + 8
28 < X < 44
|
Tinggi
|
M + 1SD < X
36 + 8 < X
44 < X
|
Kita sudah mendapatkan kriteria penentuan kategorisasi,
selanjutnya kita tinggal mencocokkan dengan data kita. Jadi misalkan si A
mendapat skor 30, maka dia memiliki asertivitas yang sedang.
Menentukan
kategori di SPSS
Jika kita memiliki data yang sedikit, misal di bawah 30,
kita masih bisa dengan mudah mengkategorikan dengan manual satu per satu. Namun
jika subjek kita ratusan, alangkah lebih mudah kalau kita memanfaatkan software
seperti Excel atau SPSS. Kali ini saya akan menjelaskan prosedur menentukan
kategorisasi dengan SPSS.
Untuk mengkategorikan data, ikuti langkah berikut
1.
Klik Transform
– Recode into different variables
2.
Masukkan skor total
ke kotak di kanan
3.
Pada output variables, isi name dengan nama variabel baru kita, misal kat_asertivitas
4.
Klik old and new values
5.
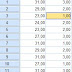
Kita akan membuat kode untuk kategori rendah dahulu.
Misal kategori rendah kita kode 1, jadi pada new value kita isi value dengan 1. Karena dari kriteria kita tadi kelompok
rendah adalah yang memiliki X < 28, maka pada bagian old value kita pilih range,
LOWEST through value dan kita isi 27,5.
Kenapa 27,5, kenapa bukan 28 saja? Karena skor 28 sudah masuk kategori sedang,
sedangkan kategori rendah adalah di bawah 28. Jadi kita ambil batasnya adalah
27,5. Lalu kalau sudah klik add. Ini
akan mengubah semua nilai yang memiliki skor dibawah 27,5 menjadi kode 1.
6.
Kita lanjut membuat kode kategori sedang. Misal kategori sedang kita kode 2, jadi pada new value kita isi value dengan 2. Karena dari kriteria kita tadi kelompok sedang adalah yang
memiliki 28 < X < 44, maka pada bagian old value kita pilih range
dan isi kotak pertama dengan 28 dan kotak kedua dengan 43,5.
Kenapa batas atasnya 43,5, kenapa bukan 44 saja? Sama seperti langkah
sebelumnya, karena 44 sudah masuk kategori tinggi, sedangkan sedang adalah
dibawah 44. Lalu kalau sudah klik add.
Ini akan mengubah semua nilai yang memiliki skor 28 sd 43,5 menjadi kode 2.
7.
Kita lanjut membuat kode untuk kategori tinggi. Misal kategori tinggi kita kode 3, jadi pada new value kita isi value dengan 3. Karena dari kriteria kita tadi
kelompok tinggi adalah yang memiliki 44 < X, maka pada bagian old value kita pilih range, value through HIGHEST dan kita
isi 44. Lalu klik add. Ini akan
mengubah semua nilai yang memiliki skor 44 ke atas menjadi kode 3.
8.
Kalau sudah, klik continue
9.
Klik change,
lalu OK
Jika kita kembali ke data kita, kita akan menjumpai
variabel baru bernama kat_asertivitas. Variabel
itu tak lain adalah kategori skor subjek pada variabel asertivitas. angka 1
menunjukkan rendah, 2 menunjukkan sedang, dan 3 menunjukkan tinggi.
Untuk mengubah label kode, kita bisa klik tab variable view di kiri bawah, lalu kita
klik pada variabel kat_asertivitas, klik kotak pada kolom values, lalu kita beri values
labels. Value 1 label rendah, lalu
klik add. Value 2 label sedang, lalu klik add. Value 3 label tinggi, lalu klik
add. Jika sudah klik OK.
Sekarang kita sudah selesai mengkategorikan subjek ke
dalam kelompok rendah, sedang, atau tinggi asertivitasnya sesuai dengan skor
skala yang diperoleh.
Menghitung
frekuensi masing-masing kelompok
Untuk mengh itung berapa jumlah subjek yang memiliki
asertivitas rendah, sedang, dan tinggi, kita dapat memanfaatkan menu frequencies
di SPSS. Caranya adalah:
1. Klik Analyze – descriptive statistics – frequencies
2.
Masukkan variabel kat_asertivitas,
lalu klik OK
3.
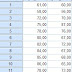
Akan keluar output seperti gambar di bawah
Sampai disini kita sudah bisa mengetahui bahwa sebagian
besar subjek memiliki asertivitas yang tinggi (59,3%), dan hanya sedikit sekali
yang memiliki asertivitas rendah (2,8%).
Prosedur di atas adalah cara mengkategorisasikan data
berdasarkan pada statistik hipotetik.
Prosedur ini dijelaskan Prof. Azwar dalam bukunya Azwar (2012) dan di jurnal
Azwar (1993). Penggunaan statistika hipotetik menggunakan alat ukur sebagai
acuan. Penggunaan prosedur ini mensyaratkan alat ukur yang digunakan adalah
alat ukur yang sudah divalidasi. Selain penggunaan statistik hipotetik,
beberapa peneliti juga menggunakan statistik
empirik. Perbedaan keduanya akan dibahas pada artikel lain.
REFERENSI
Azwar, S. (1993). "Kelompok subjek ini memiliki
harga diri yang rendah"; kok, tahu...? Buletin
Psikologi, I(2), 13-17.
Azwar, S. (2012). Penyusunan
Skala Psikologi edisi 2. Yogyakarta: Pustaka Pelajar